
Tags
- Article & User
- 완전검색
- DB
- Django
- 트리
- ORM
- 백트래킹
- SQL
- 쟝고
- N:1
- 뷰
- delete
- outer join
- 통계학
- Vue
- 그리디
- update
- migrations
- 이진트리
- count
- drf
- 스택
- Tree
- M:N
- regexp
- 큐
- Queue
- stack
- distinct
- create
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
Notice
Recent Posts
Link
데이터 분석 기술 블로그
Variance (분산) 본문
분산(Variance)은 확률 변수의 값이 평균(기댓값)을 기준으로 얼마나 퍼져 있는지(산포도)를 수치로 나타내는 척도이다.
기댓값이 '중심'이라면, 분산은 '흩어짐의 정도'라고 생각하면 된다.
정의
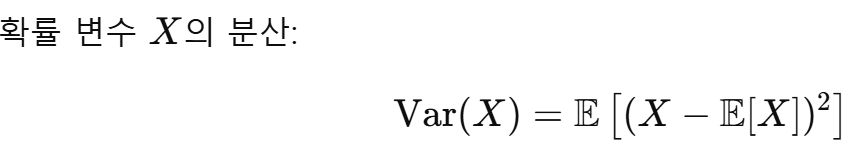
즉, 기댓값으로부터의 거리(오차)의 제곱의 평균
→ 항상 0 이상이며, 값이 클수록 불확실성도 큼
분산의 대체 공식 (shortcut formula)
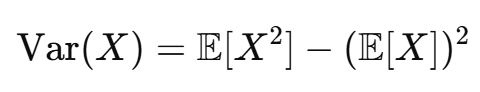
상수와의 연산

- 분산은 평균 이동에는 영향 없음,
- 스케일(크기)에는 제곱 배로 커짐
독립 확률 변수의 분산
확률 변수 X, Y가 독립이라면:

일반적으로는 다음과 같이 공분산을 포함해야 한다:
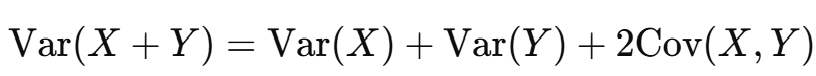
표준편차 (Standard Deviation)

→ 분산은 제곱 단위라서, 원래 단위로 되돌릴 땐 표준편차를 사용
'데이터 사이언스 > 수리 통계학' 카테고리의 다른 글
| Covariance and Correlation (공분산과 상관계수) (0) | 2025.04.11 |
|---|---|
| Moments, Skewness and Kurtosis (모멘트, 비대칭도, 첨도) (0) | 2025.04.10 |
| Properties of the Expected Value (기댓값의 성질) (0) | 2025.04.08 |
| Expected Value and Mean (기댓값과 평균) (0) | 2025.04.07 |
| Convolution From Adding Random Variables (확률 변수의 합과 컨볼루션) (0) | 2025.04.06 |
'데이터 사이언스/수리 통계학' Related Articles
more



